Le problème : anticiper la montée des eaux
La Vilaine, principal fleuve de Bretagne, traverse un bassin versant où les crues hivernales constituent un risque récurrent. En janvier 2025, une crue majeure a encore rappelé la vulnérabilité des communes du bassin amont, de Vitré à Châteaubourg.
Les modèles hydrologiques classiques (conceptuels ou physiques) sont précieux, mais leur mise en œuvre reste lourde et leur adaptation au temps réel limitée. L'objectif de ce projet : construire un modèle de machine learning opérationnel capable de fournir des prédictions fiables de hauteur d'eau (H) et de débit (Q) sur 11 stations simultanément, avec un horizon de 1 à 24 heures, et des intervalles de confiance pour quantifier l'incertitude.

Le bassin couvre 4 cours d'eau — la Vilaine (axe principal), la Valière, la Cantache et la Veuvre/Chevré — avec 3 barrages dont les lâchés d'eau influencent directement la dynamique de crue en aval. Le temps de propagation entre l'extrémité amont (Bourgon) et l'aval (Cesson-Sévigné) est de 11 à 27 heures selon le débit, ce qui correspond bien à notre horizon de prédiction de 24h.
Les données : croiser hydrologie et météo
Un bon modèle commence par de bonnes données. J'ai collecté et croisé deux sources complémentaires, couvrant la période 2000 – 2026 :
Données hydrologiques — API Hydro EauFrance
Pour chacune des 11 stations du bassin (de l'amont vers l'aval), j'ai récupéré les séries horaires de hauteur d'eau (H) et de débit (Q) via l'API publique Hydro EauFrance. L'API ne retourne qu'un an de données par requête : le script de collecte découpe donc automatiquement la plage en segments annuels, gère les retries, et fonctionne en mode incrémental — relancer la collecte ne récupère que les nouvelles données.
Données météo — Open-Meteo
Pour chaque station, j'ai collecté les précipitations horaires (mm/h) et l'humidité du sol (couches 0-7 cm et 7-28 cm) depuis l'API gratuite Open-Meteo. L'humidité du sol est un indicateur précieux : un sol déjà saturé amplifie considérablement le ruissellement lors d'un épisode pluvieux.
Préparation des features
Les données brutes passent par un pipeline de transformation en 7 étapes pour aboutir à un dataset prêt à l'entraînement. Chaque station est caractérisée par 7 variables à chaque pas de temps :
Les features dérivées (dH/dt et dQ/dt) capturent la dynamique — est-ce que le niveau monte ou descend, et à quelle vitesse ? Pour les 3 stations situées en aval de barrages, j'ai ajouté une feature "release" qui détecte les lâchés d'eau : une baisse de hauteur sans pluie associée est un signal caractéristique d'une ouverture de vanne.
La normalisation utilise les percentiles P1/P99 plutôt que min/max, ce qui la rend robuste aux valeurs extrêmes tout en préservant l'information sur les crues.
Architecture du modèle
L'architecture que j'ai conçue, baptisée Station-Attention, combine trois idées clés : traiter chaque station comme une entité distincte, laisser les stations "se parler" entre elles via de l'attention, et quantifier l'incertitude nativement.
72h × 7 variables × 11 stations
Prévisions 24h par station
Chaque station encodée indépendamment → 1 embedding / station
8 têtes · Les stations échangent de l'information spatiale
Hauteur d'eau
Débit
11 stations × 24 horizons × 3 quantiles (q10, q50, q90)
Pourquoi un LSTM partagé ?
Un même réseau LSTM traite les 11 stations, ce qui force le modèle à apprendre des patterns hydrologiques génériques (montée de crue, décrue, réponse à la pluie) plutôt que des particularités locales. Chaque station entre avec ses 7 variables propres et ressort sous forme d'un vecteur (embedding) qui résume sa dynamique récente.
L'attention multi-station : la pièce maîtresse
C'est la couche d'attention croisée (Multi-Head Attention, 3 couches × 8 têtes) qui donne sa puissance au modèle. Concrètement, elle permet à chaque station de consulter l'état des autres pour affiner sa propre prédiction. Si une station amont montre une montée rapide, les stations aval "savent" qu'une onde de crue approche, même si localement rien ne s'est encore passé. Ce mécanisme capture naturellement la propagation spatiale et temporelle des crues le long du bassin.
Quantile regression : mesurer l'incertitude
Plutôt qu'une seule valeur prédite, le modèle fournit trois quantiles pour chaque prédiction : q10 (borne basse), q50 (prédiction médiane), et q90 (borne haute). Cela donne un intervalle de confiance à 80% directement exploitable pour la gestion du risque.
Exemple de prédiction avec intervalles de confiance
Entraînement : les détails qui comptent
Le modèle est implémenté en PyTorch et entraîné sur un NVIDIA DGX Spark équipé d'un GPU Blackwell GB10 avec 128 Go de mémoire unifiée — un confort appréciable pour manipuler 25 ans de données sur 11 stations.
Fonction de perte asymétrique
J'utilise une pinball loss (loss standard de la quantile regression) avec une pénalité asymétrique spécifique : en période de crue, sous-estimer le niveau d'eau est beaucoup plus grave que le surestimer. Quand la hauteur à Châteaubourg dépasse 800 mm, la pénalité de sous-estimation est doublée. C'est un choix métier autant que technique.
Suréchantillonnage des crues
Les crues sont par nature des événements rares dans les données. Sans correction, le modèle serait excellent en régime normal mais médiocre en crue — précisément le moment où la précision compte le plus. J'ai mis en place un suréchantillonnage progressif des périodes de crue dans le jeu d'entraînement :
Stratégie d'entraînement
L'optimisation utilise AdamW avec weight decay, un warmup linéaire sur 5 epochs suivi d'un scheduler ReduceLROnPlateau. Le gradient est clippé à 1.0 pour stabiliser l'entraînement. Un early stopping avec patience de 20 epochs sur la validation loss surveille le surapprentissage.
Le split des données est strictement chronologique pour éviter toute fuite d'information : 25,5 ans d'entraînement (2000 – juin 2025), 6 mois de validation (juillet – décembre 2025), et l'hiver 2025-2026 en test.
Résultats
Les métriques ci-dessous sont mesurées sur le jeu de test (hiver 2025-2026, données jamais vues pendant l'entraînement), à la station de Châteaubourg — la station de référence du bassin. La prédiction porte sur le quantile médian (q50).
Prédictions en temps réel — Châteaubourg, février 2026
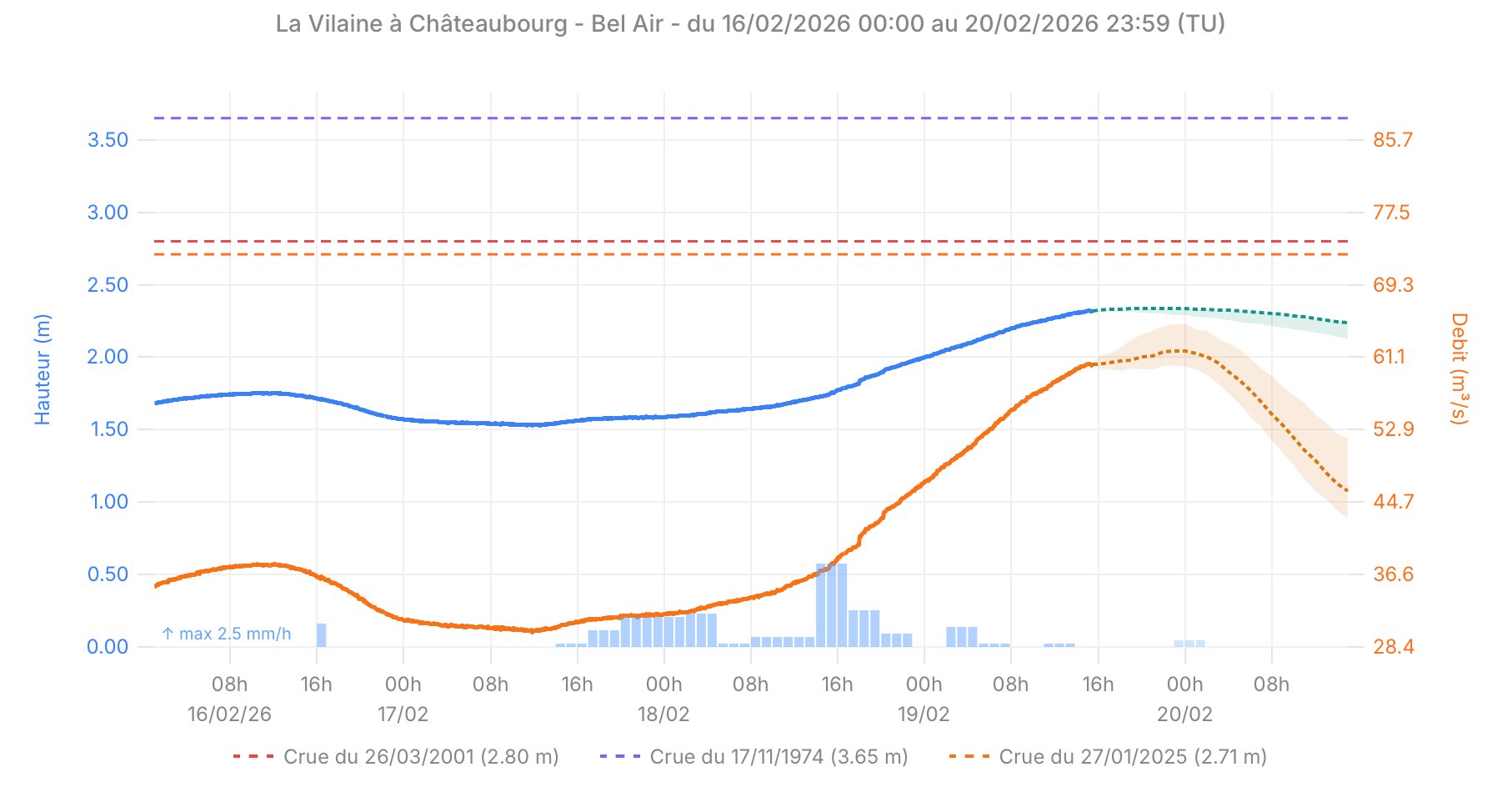
Hauteur d'eau (bleu) et débit (orange) observés et prédits à Châteaubourg. Les bandes colorées représentent l'intervalle de confiance [q10 – q90]. Les lignes pointillées indiquent les niveaux des crues historiques de référence.
| Horizon | NSE | RMSE | Interprétation |
|---|---|---|---|
| t + 1h | 0.9999 | 6 mm | Quasi-parfait — le modèle a une inertie naturelle très forte |
| t + 6h | 0.9967 | 36 mm | Excellent — bien au-delà du seuil d'utilité opérationnelle |
| t + 12h | 0.9887 | 67 mm | Très bon — l'incertitude augmente mais reste maîtrisée |
| t + 24h | 0.9710 | 108 mm | Bon — un NSE > 0.97 à J+1 est un résultat solide |
Le NSE (Nash-Sutcliffe Efficiency) est la métrique de référence en hydrologie. Un NSE de 1 signifie une prédiction parfaite, un NSE de 0 signifie que le modèle ne fait pas mieux que la moyenne historique. En pratique, un NSE supérieur à 0.75 est considéré comme "bon" et au-dessus de 0.90 comme "excellent". Nos résultats se situent bien au-delà de ces seuils, y compris à 24 heures d'horizon.
Mise en production
Un modèle qui ne tourne qu'en notebook n'a pas beaucoup de valeur. Le pipeline est conçu de bout en bout pour une mise en production réelle :
Le modèle PyTorch est exporté au format ONNX, un format standard qui permet l'inférence depuis n'importe quel langage. En l'occurrence, le modèle tourne dans un backend Node.js via onnxruntime-node, ce qui élimine la dépendance à Python en production. Les paramètres de normalisation et les métadonnées sont également exportés pour garantir que le prétraitement en inférence est identique à celui de l'entraînement.
La collecte de données tourne en continu avec les mêmes scripts que ceux utilisés pour l'entraînement — en mode incrémental — garantissant la cohérence entre les données d'entraînement et de production.
Stack technique
Ce que ce projet illustre
Au-delà des résultats chiffrés, ce projet illustre une approche complète du machine learning appliqué — de la collecte de données brutes jusqu'au déploiement en production. Concevoir un modèle performant, c'est aussi savoir construire un pipeline robuste, choisir une architecture adaptée au problème métier, et prendre les bonnes décisions d'ingénierie (loss asymétrique, suréchantillonnage, export ONNX…).
C'est exactement le type de mission que je réalise en tant que freelance : transformer une problématique métier en un système de machine learning opérationnel, fiable, et maintenable.
Voir le projet : vilaine-amont.haruni.net · Code source sur GitHub · Modèle sur Hugging Face